Indexing and Slicing Strings
由于Go strings存储的是UTF-8编码后的字节,所以在slice一个字符串是需要特别注意字符的边界问题。 这对于7-bit的ASCII文本来说容易,因为每个字符由一个字节构成。但对于non-ASCII文本来说,每一个字符由一个或者多个字节组成,所以不好直接分隔出子串. 通常我们并不需要对一个字符串进行slice. 只是需要通过for ... range loop进行遍历。但在一些情况下,我们确实需要通过slice提取字符串的子串. 这时我们可以使用strings.Index() 或者 strings.LastIndex()来确定字符index. strings package如Tables 3.6所示.
我们将开始以不同的方式来感知一个字符串。Index positions —— 它表示的是string中字节的位置——从0到字符串的长度减1。也可以从后往前数Len(s)-n表示的是从右开始数,第n个字节。 比如 s := "naïve". 如图3.1所示表示字符串s的Unicode characters, Code points 和 bytes 以及两个字符slice.

如图3.1,每一个index位置, 都可以使用[] index operator返回正常的ASCII字符(一个字节)——比如,s[0] == 'n' and s[len(s)-1] == 'e'. ï字符的开始位置是2. 但如果我们使用s[2] 我们只能获得字符ï的第一个字节(0XC3).这样的字节很少是我们想要的。
对于只包含7-bit ASCII的字符的字符串来说,我们可以通过s[0]获得第一个字符。 s[len(s)-1]获得最后一个字符。但通常我们应该使用utf8.DecodeRuneInString()来获得第一个字符, 使用utf8.DecodeLastRuneInString()获得最后一个字符。
如果我们真的需要索引出单个字符。我们有多种选择。对于只包含7-bit ASCII来说,我们只需要简单的使用[]索引操作符, 0(1)的检索时间. 对于非ASCII字符串,我们可以将它转换为[]rune,之后在使用[]索引操作符。但会多出一个0(n)的转换的花销.
对于我们的例子来说, 如果我们使用了 chars := []rune(s). chars将会是由5 code point组成的 []rune。 而不是由6个字节byte组成.
对于任何包含non-ASCII的字符串来说, 很少通过索引index提取出字符. 更好的办法是使用string slicing —— 返回一个字符串,而不是一个byte.
现在让我们看一个slice的实际例子,假设有一行文本,我们提取出行的第一个和最后一个单词。代码如下
line := "røde og gule sløjfer"
i := strings.Index(line, " ") // Get the index of the first space
firstWord := line[:i] // Slice up to the first space
j := strings.LastIndex(line, " ") // Get the index of the last space
lastWord := line[j+1:] // Slice from after the last space
fmt.Println(firstWord, lastWord) // Prints: røde sløjfer
虽然这个例子对于空格以及其它的7-bit ASCII字符来说可以正常使用。 但不适用于其它任意的Unicode空白字符,比如U+2028(行分隔符)或者U+2029(段落分隔符).
以下是一个改进的方法,可以不管空白是什么字符。
line := "rå tørt\u2028vær"
i := strings.IndexFunc(line, unicode.IsSpace) // i == 3
firstWord := line[:i]
j := strings.LastIndexFunc(line, unicode.IsSpace) // j == 9
_, size := utf8.DecodeRuneInString(line[j:]) // size == 3
lastWord := line[j+size:] // j + size == 12
fmt.Println(firstWord, lastWord)
strings.IndexFunc()函数遍历第一个参数字符串,并会每一次遍历到的字符传递给第二个参数(func(rune) bool), 如果第二个参数(函数)返回true, 则strings.IndexFunc()返回这个字符的位置。 而strings.LastIndexFunc()则返回最后一个满足要求的位置。 这里我们都是使用unicode包的 IsSpace()函数作为第二个参数。 这个函数接受一个code point(rune 类型), 如果这个字符是一个空白字符,则返回true.
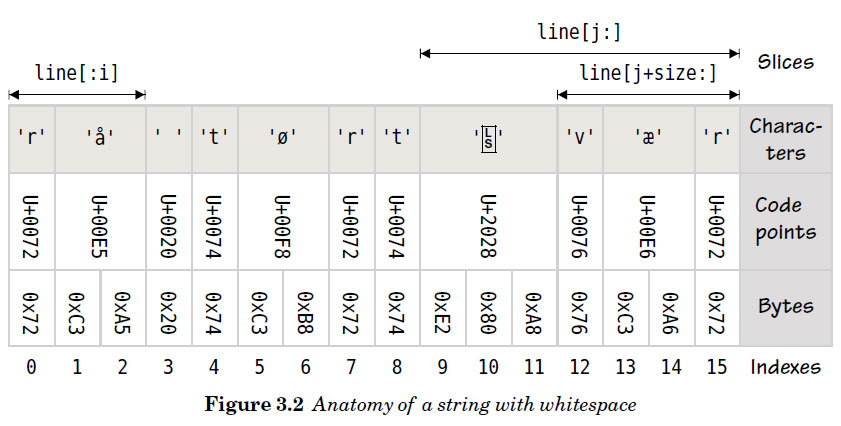
完成第一步非常容易,但对于搜索最后一个空白字符时,我们必须非常小心。因为有的空白字符的是由多个字节组成,而不是单个。所以我们需要使用到utf8.DecodeRuneInString()函数返回第一个字符的字节大小。