Key Concepts
在并发编程中,我们通常处理过程划分到多个goroutine中,然后当计算完成时直接输出结果,或者在聚合它们的结果。
即使是Go的高级并发编程,这里有一些陷阱需要我们避免。比如当一个程序在完成是,却没有产生结果。Go的程序会在main goroutine终止时终止——即使这时还有其它的goroutine在处理数据——所以我们必须小心的维护main goroutine到所以有工作完成。
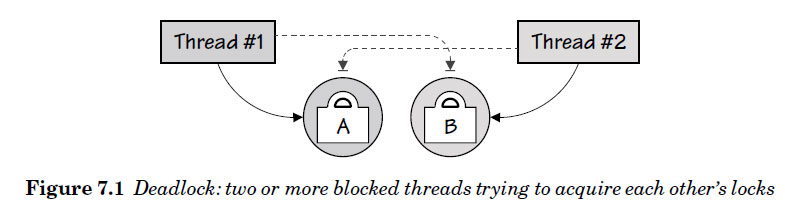
另一个陷阱时我们必须避免死锁。这个问题跟上面的例子是相反的: main goroutine和所有的处理goroutine在所有的任务完成时,却依然存在。这通常是由于没能正常报告完成的进度。另一个引起死锁的原因是,当两个不同的goroutines(或者线程)都使用了锁来保护资源,并且相同的时间尝试获取相同的锁,如图7.1所示. 这种死锁只在锁已被使用时发生,这在其它语言中很常见,但Go很少见,因为Go应用程序可以避免使用锁,而使用channels代替。
对于避免程序过早终止或者不终止的常见方法是让main goroutine等待一个"done" channel来报告整个的处理进度(我们之后会在之后看到).(这里也可以使用一个哨兵值作为最后的“result”发送给main goroutine, 但这相对于方法来说,显得比较笨拙).
另一种避免这种陷阱的方法是使用sync.WaitGroup等待所有的处理go协程报告它们是否处理完成。可是,使用sync.WaitGroup自身也会引发死锁,特别是当所有的处理goroutine被阻塞时(e.g.,等待接收一个channel),而又在main goroutine上调用sync.WaitGroup.Wait()方法。我们将在之后展示,如何使用sync.WaitGroup.
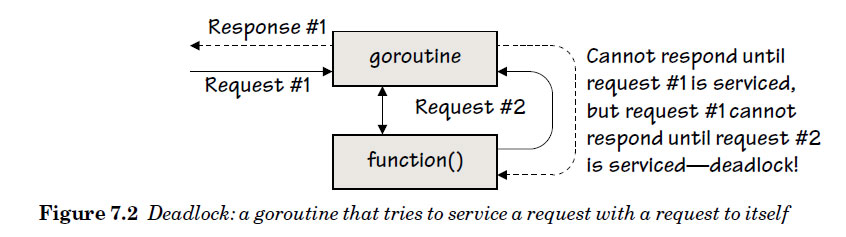
即使用仅使用channels,而没有使用锁,依然会在Go中产生死锁。比如,假设我们有一组goroutine,它们彼此要求另一个去执行函数(e.g.,通过彼此发送请求). 现在如果其中一个已请求的函数,向一个正在执行的goroutine做了一个发送——比如,给它传递一些数据——我们就会获得一个死锁。如图7.2所示。
channel为两个并发运行的goroutines提供了无锁通信(在channel底层实现上会使用到锁,但我们不需要关心它的实现细节)。
默认的channels是双向的,即我们可以向它发送值,也可以从它获取值。但是,作为参数传递的struct的字段或者一个channel,它将只能单向的,只可以用来发送或者从它们那接收。这种情况下,我们可以通过指定channel的方向来明确我们想要什么(并且强制编译器为我们检查)。比如,使用创建一个channel时,使用chan<- Type, 表明这是一个仅用于发送的channel. 而<-chan Type仅用于接收的channel。我们在之前的章节中没有使用到这种方法,这是因为我们总是可以使用chan Type代替。但是从现在开始,只要出现合适于使用单向channel时,我们就将使用单向channel, 因为它们会在编译时会提供额外的编译检查,同时也是最佳的实践。
如果向channel发送的值为bools, ints, float64类型,本质上是安全的,因为它们是会被复制。所以在并发访问相同的值是没有风险。相似的,如果发送的值为strings,则这也是安全的,因为字符串是不可变的。
发送指针或者引用(e.g., slices, maps)则是不安全的,因为指针指向的值或者引用的值可能被发送的goroutine修改,所以在接收端的goroutine中,会接受到不可预期的接果。所以,当发送指针和引用时,我们必须确保在任何时间,仅能被一个goroutine访问,也就是说,访问必须串行化。可以例外的是,文档指明了传递指针是安全的,比如, *regexp.Regexp可以被安全的在多个goroutine中使用,因为在*regexp.Regexp上的所有方法都不会改变这个值的状态。
一个串行访问的方法是使用互斥器(mutexes). 另一种是应用策略来约束一个指针或者引用仅可以发送一次,并且一旦发送给channel,就不能在访问。基于策略的缺点是要求纪律性。第三种方法是为要传递的指针或者指点用的值提提供公有方法(导出方法),而这些导出方法不可以修改指针或者引用的值,而非导出方法可以执行修改。这样的指针或者引用就可以通过它们导出的方法来发送和访问。同时仅有一个goroutine允许使用它们的非导出方法(e.g.,在它们自已的package内部,我们将在第9章中讲解).
我们也可以channel声明是使用接口——这就是说,发送的值必须满足这个特定的接口。对于只读的接口类型的值,可以安全的被任意数量goroutine使用,但接口类型的值包含了可以修改值状态的方法,我们必须向对待指针那样,进行序列化的访问。
举例来说,哪果我们通过image.NewRGBA()函数,创建了一个新的图片,我们将获得一个*image.RGBA的指针。这种类型满足image.Image接口(这个接口只有访问方法,所以它是只读的)和draw.Image接口(包含接口image.Image的所有方法,同时还有一个Set()方法)。所以*image.RGBA可以传递给任意数量的goroutines——只要函数接受一个image.Image接口。(但不幸的是,如果在接收方法中使用type assertion了,就可能破坏这种安全性,即在断言中使用了draw.Image. 所以明确的策略是不允许这种事情的发生)。而如果我们想要在多个goroutine中使用*image.RGBA,并且要修改这个值。我们确保对这个值是串行访问的。
使用并发的最简单方式之一是使用一个goroutine来做准备工作,而其它的goroutine做详细的工作,让main goroutine和一些channels来安排所有的事情,比如,以下这个例子,我们在main goroutine中创建了一个"jobs"的channel和"done" channel。
jobs := make(chan Job)
done := make(chan bool, len(jobList))
在这里我们创建了一个非缓冲的jobs channel,用来传递自定义的Job类型。我们也创建了一个缓冲的done channel, 它缓冲的大小跟jobList中的job数量一致。([]Job, jobList的初始化没有在这里显示)。
channels和job list设置好后,我们就可以开始了
go func() {
for _, job := range jobList {
jobs <- job // Blocks waiting for a receive
}
close(jobs)
}()
这段代码里创建了第一个额外的goroutine. 它遍历了jobList slice, 并且将jobList中的job发送到 jobs channel. 由于channel是非缓存的,所以goroutine立即被阻止,直到其它的goroutine尝试从jobs channel中获取一个job. 一旦所有的jobs被发送到jobs channels后,这个channel将被关闭,所以接收者将能知道何时没有job了。
这段代码看起来并非显而易见的,简单的看起来只是一个for循环,循环后结束后关必jobs channel——但其实这里发生了并发。在这里go语句会立即返回,只让它后面的代码在一个新的goroutine中运行——如果这个时候没有人尝试从jobs channel中获取job. 这个goroutine将被阻塞。所以,在这个go语句之后,程序有两个goroutine, main goroutine和这个新创建的goroutine. main goroutine将从下一条语句后继续执行,而新的goroutine将被阻塞,等待其它goroutine从jobs channel中获取一个job. 因此,在for循环和channel关闭之前,将需要一些时间。
go func() {
for job := range jobs { // Blocks waiting for a send
fmt.Println(job) // Do one job
done <- true
}
}()
这段代码创建了第二个goroutine. 这个goroutine遍历jobs channel, 接收到一个job后,对它进行处理(这里只是简单的打印它),在处理完后,向done channel发送一个true(我们也可以发生false, 因为我们只关注有多个job完成了,而不关心发送到done channel中的实际值是什么)。
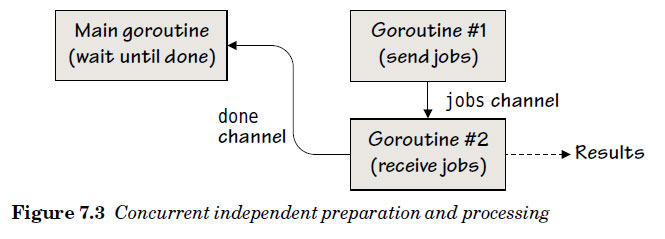
跟第一条go语句一样,这条语句会立即返回,然后for语句会被阻塞,等待一个发送。所以这时,有三个并发的goroutine在执行——main goroutine和两个额外的goroutine. 如图7.3所示。
由于我们已经有一个发送等待(在goroutine), 所以这个等待发送的job可以立即被接收和处理(通过goroutine). 期间goroutine #1在次被阻塞,用于等待发送第二个job. 一旦goroutine #2完成job的处理,并将发送一个true给done channel——这个channel是可缓冲的,所以不会阻塞发送。然后goroutine #2的控制流返回到for循环,goroutine #1发送下一个job, 然后goroutine #2在接收,直到所有的jobs完成。
for i := 0; i < len(jobList); i++ {
<-done // Blocks waiting for a receive
}
最后一段代码会在两个额外的goroutine创建和开始执行后立即执行。这段代码是main goroutine中,它用于保证main goroutine不会立即终止,直到所有的工作完成。
for循环遍历的次数跟job的数量相关,每一次遍历都跟已经完成的job同步。如果这里在一次遍历中,没有接收到值(i.e.,一个job已经在做,但还没有完成),这次接收就会发生阻塞。一旦完成了所有的jobs,done channels的发送和接收次数等于for循环的遍历次数,for循环也将最终完成。这时整个main goroutine完成, 然后终止程序,这样我们就能保证所有的处理被完成。
在使用channels中有两条经验,第一条,我们仅需要在一个channel之后会用于校验它是会关闭的情况下,才需要明确的关闭一个channel.(这种校验可以发生在for ... range,如第二个goroutine. 一个select, 或者一个使用了<-操作符用来确认是否有接收)。第二条,一个channel的关闭应该在发生端的goroutine, 而不应该在接收端。对于不会用于检查关闭的channel, 我们可以不用于管它,因为channels非常轻量,所以它们不会像打开一个文件那样占用资源。
在这个例子中,jobs channels是通过使用for...range 循环遍历的,依据我们的经验,所以我们发送端goroutine关闭它。但对于另外两个channel,我们不需要关闭,因为没有语句依赖它们是否关闭。
这个例子演示了一种在Go并发编程中的常见模式,尽管在这种情况下并发并不是最好的选择。之后的例子都是使用跟这个相似的模式——并且允分利用并发性。