Arrays and Slices
Go数组是固宽长度的相度类型元素组成的序列。 数组元素的索引是通过[]索引操作符,从0位置开始。 所以数组的第一个元素是array[0], 而最后一个数组是array[len(array)-1].
数组的创建可以使用如下语法
[length]Type
[N]Type{value1, value2, ..., valueN}
[...]Type{value1, value2, ..., valueN}
如果在语义中使用了...(省略号)操作符。Go将会自动为我们计算数组的长度。(...省略号操作符也可以用于其它目的,比如将一个slice添加到另一个slice上)。 在所以的语法中, 数组的长度是固定并且不能在被修改。
以下这下例子是如何创建数组和索引数组。
var buffer [20]byte
var grid1 [3][3]int
grid1[1][0], grid1[1][1], grid1[1][2] = 8, 6, 2
grid2 := [3][3]int{{4, 3}, {8, 6, 2}}
cities := [...]string{"Shanghai", "Mumbai", "Istanbul", "Beijing"}
cities[len(cities)-1] = "Karachi"
fmt.Println("Type Len Contents")
fmt.Printf("%-8T %2d %v\n", buffer, len(buffer), buffer)
fmt.Printf("%-8T %2d %q\n", cities, len(cities), cities)
fmt.Printf("%-8T %2d %v\n", grid1, len(grid1), grid1)
fmt.Printf("%-8T %2d %v\n", grid2, len(grid2), grid2)
Output
Type Len Contents
[20]uint8 20 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[4]string 4 ["Shanghai" "Mumbai" "Istanbul" "Karachi"]
[3][3]int 3 [[0 0 0] [8 6 2] [0 0 0]]
[3][3]int 3 [[4 3 0] [8 6 2] [0 0 0]]
当我们在创建数组时,只初始部份或者没有指定初始值,Go会为没有指定的元素赋值此类型的零值。 如buffer, grid1, grid2所示。
通过len()函数可以获得一个数组的长度。由于数组固定了容量的大小,并组等于它的长度,所以cap()函数跟len()函数返回相同的值。数组也可以像对字符串或者slices那样的语法进行切片。 数组也可以使用 for ... range循环来遍历它的元素。
通常, Go slice类型要比数组更灵活,强大和方便。 数组是通过值传递(i.e., copied)——虽然也可以通过传递指针来避免。然而slice是廉价的传递的,跟lenght和capacity无关。 因为它们是引用类型(64位的机器上是16字节,32位的机器上是12字节,而不管包含多少个无素). 数组是固定大小的,而slice可以调整大小。 Go标准库中的函数都是使用slices而没有使用数组。 所以我们推荐slices,除非在一些特定的情况下,需要使用到array. 对数组和slice进行裁剪的语法如表4.1所示.
Go slice类型是由相同类型的元素组成的可变长度,固定容量的序列。 尽管它们是固定容量, slice依然可以通过切片(slicing)来进行缩小和通过内置的append()函数增加容量。 多维slice是由此类型的slice组成,多维slice内部的元素长度是可以不同的。
虽然数组和slice存储的是相同的类型,但在实际操作中并没有这样的限制。 这是因为类型可以使用interface. 所以我们可以存储任意类型的元素,只要它们符合指定的接口(i.e., 此类型的方法符合interface的要求). 甚至我们可以指定数组或者slice的类型为空接口, interface{}, 这样我们可以用它保存所有的类型,虽然这样我们可以访问到元素。 但在使用元素时,确需要使用到type assertion(类型断言) or type switch or introspection.
Slice创建语法如下所示
make([]Type, length, capacity)
make([]Type, length)
[]Type{}
[]Type{value1, value2, ..., valueN}
内置的make()函数用来创建slices, maps, channels. 当我们创建一个slice时,它同时创建了一个隐藏的数组,并且初始化数组的值为零值, 并返回一个slice reference(它又引用了隐藏的数组). 这个隐藏的数组跟所有的数组一样,长度是固定的,如果使用的是第一种语法,指名了capacity, 则这个隐藏数组的长度等于capacity. 如果是第二种语法,则是length的长度。 如果是第三或者第四种语法,则长度是花括号包含元素的个数。通过以下代码,我们可以更好的更解Slice 切片与数组的关系
array := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
var slice1, slice2 []int //声明为slice.
slice1 = array[:4]
slice2 = array[3:7]
fmt.Println("slice1:", slice1)
fmt.Println("slice2:", slice2)
slice1[3] = 100
fmt.Printf("%d\n", cap(slice1))
fmt.Println("slice1:", slice1)
fmt.Println("slice2:", slice2)
/*
slice1: [1 2 3 4]
slice2: [4 5 6 7]
10
slice1: [1 2 3 100]
slice2: [100 5 6 7]
*/
一个slice的容量是它隐藏数组的长度减去它从隐藏数组的索引的位置,而length是slice实际包含的元素的个数,但小于等于capacity.
Table 4.1 Slice Operations
| Syntax | Description/result |
|---|---|
| s[n] | The item at index position n in slice s |
| s[n:m] | A slice taken from slice s from index positions n to m - 1 |
| s[n:] | slice taken from slice s from index positions n to len(s) - 1 |
| s[:m] | A slice taken from slice s from index positions 0 to m - 1 |
| s[:] | A slice taken from slice s from index positions 0 to len(s) - 1 |
| cap(s) | The capacity of slice s; always ≥ len(s) |
| len(s) | The number of items in slice s; always ≤ cap(s) |
| s = s[:cap(s)] | 如果它的容量跟长度不同,则增加slice的长度为它的容量 |
[]Type{}语法跟make([]Type, 0)是相同的,两者都是创建一个空的slice.
slice中有效的索引范围是从0到len(slice)-1. 一个slice可以被再次切割,以减小它的长度。 并且如果一个slice的capacity比它的长度大时,可以通过再切片,使用它的长度达到容量的大小。 我们也可以使用append()函数,增加 capacity.
如图4.3所示,我们可以看到slice和它的隐藏数组之间的关系。
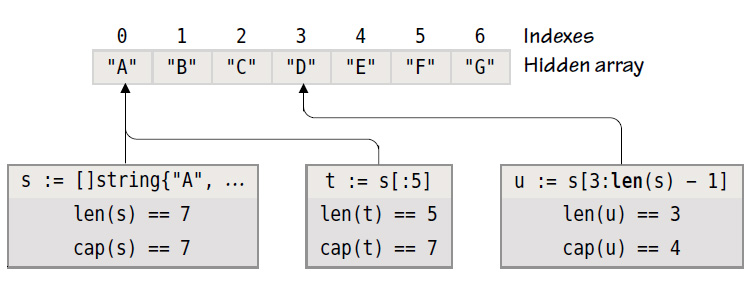
s := []string{"A", "B", "C", "D", "E", "F", "G"}
t := s[:5] // [A B C D E]
u := s[3 : len(s)-1] // [D E F]
fmt.Println(s, t, u)
u[1] = "x"
fmt.Println(s, t, u)
/*
[A B C D E F G] [A B C D E] [D E F]
[A B C D x F G] [A B C D x] [D x F]
*/
由于slice s, t, u都是相同的底层数组。 改变其中一个,则其它的也跟着改变。
s := new([7]string)[:]
s[0], s[1], s[2], s[3], s[4], s[5], s[6] = "A", "B", "C", "D", "E", "F","G"
在实际我们都是使用make()函数或者 []Type{}的语法来创建slice. 但这里我们更明显的展示array-slice之前的关系,我们在第一条语句中使用了内置的new()函数,创建了一个指向数组的索引,并且立即对这个数组进行切片,返回一个包含所有数组元素的slice(长度和capacity等于数组的长度, 每一个元素为零值,在这里为空字符串). 第二条语句我们分别设置了每个元素的值, 完成这一步之后,所创建的slice跟之前通过[]Type{value1, value2,...,valueN}创建的slice一样。
我们举一个之前在array出现过的例子
buffer := make([]byte, 20, 60)
grid1 := make([][]int, 3) //slice 并初始化一维数组的长度为3, capacity 3
for i := range grid1 {
grid1[i] = make([]int, 3)
}
grid1[1][0], grid1[1][1], grid1[1][2] = 8, 6, 2
grid2 := [][]int{{4, 3, 0}, {8, 6, 2}, {0, 0, 0}}
cities := []string{"shanghai", "Mumbai", "Istanbul", "Beijing"}
cities[len(cities)-1] = "Karachi"
fmt.Println("Type Len Cap Contents")
fmt.Printf("%-8T %2d %3d %v\n", buffer, len(buffer), cap(buffer), buffer)
fmt.Printf("%-8T %2d %3d %v\n", cities, len(cities), cap(cities), cities)
fmt.Printf("%-8T %2d %3d %v\n", grid1, len(grid1), cap(grid1), grid1)
fmt.Printf("%-8T %2d %3d %v\n", grid2, len(grid2), cap(grid2), grid2)
/*
Type Len Cap Contents
[]uint8 20 60 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[]string 4 4 ["Shanghai" "Mumbai" "Istanbul" "Karachi"]
[][]int 3 3 [[0 0 0] [8 6 2] [0 0 0]]
[][]int 3 3 [[4 3 0] [8 6 2] [0 0 0]]
*/
我们可以看到buffer的内容只有len(buffer)个元素, 其它的元素是不可以访问的,除非我们reslice这个buffer.
我们创建了grid1, 它的长度为3(可以包含3个slice), 同时容量也为3(如果没有明确指定,capacity默认为length大小). 然后我们在一个for循环中指定最外层slice元素(每一个外层元素可以在包含三个int), 当然也可以为最里面的slice,指定不同的int元素.
Indexing and Slicing Slices
一个slice是引用了一个隐藏数组,同时对一个切片的切片(对一个slice进行切片)也是引用相同的隐藏数组。通过以下的例子,你可以更好的理解这个意思
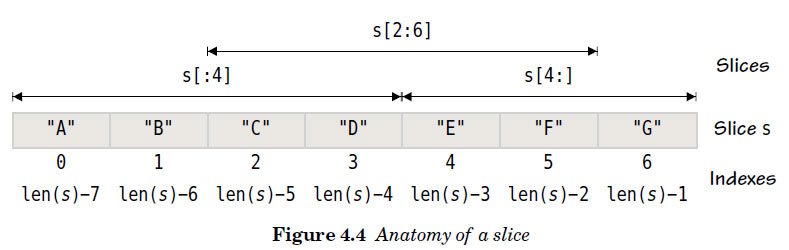
s := []string{"A", "B", "C", "D", "E", "F", "G"}
t := s[2:6]
fmt.Println(t, s, "=", s[:4], "+", s[4:])
s[3] = "x"
t[len(t)-1] = "y"
fmt.Println(t, s, "=", s[:4], "+", s[4:])
/*
[C D E F] [A B C D E F G] = [A B C D] + [E F G]
[C x E y] [A B C x E y G] = [A B C x] + [E y G]
*/
无论我们通过s或者t(slice of s slice)都可以改变底层的数据。 这段代码也展示了slice s和索引位置i(0 ≤ i ≤ len(s)). s等于 s[:i] 和 s[i:4]的连接. 这跟我们在上一章中字符串的类似
s == s[:i] + s[i:] // s is a string; i is an int; 0 <= i <= len(s)
跟字符串不同,slices不支持 + 或者 +=操作符。但是slice对于添加和删除元素也非常简单,我们稍后会讲解到.
遍历Slices
一个常见的需求就是遍历一个slice中的所有元素。 如果我们只想访问一个元素,而不需要修改它们,则可以使用for ... range loop. 而如果我们需要修改元素,则需要使用for loop 跟一个循环计数器。 以下是一个之前讲过的例子
amounts := []float64{237.81, 261.87, 273.93, 279.99, 281.07, 303.17,
231.47, 227.33, 209.23, 197.09}
sum := 0.0
for _, amount := range amounts {
sum += amount
}
fmt.Printf("Σ %.1f → %.1f\n", amounts, sum)
/*
Σ [237.8 261.9 273.9 280.0 281.1 303.2 231.5 227.3 209.2 197.1] → 2503.0
*/
for ... range loop 从0开始计数,在这里我们将它赋值给一个空白符(_),以舍弃索引位置。 同时从slice中复制相应的元素到account, 这个复制是廉价的。 这个意思是任何对元素的改变,只会影响到这个副本。 而不会影响到slice中的元素。
自然,我们也可以一个slice的一部分。 比如,我们只想遍历前5个元素,for _, amount := range amounts[:5].
如果我们需要修改一个slice中的元素,我们必须使用for loop。 这个循环只提供元素的索引位置index. 而不会复制slice的元素.
for i := range amounts {
amounts[i] *= 1.05
sum += amounts[i]
}
fmt.Printf("Σ %.1f → %.1f\n", amounts, sum)
//Σ [249.7 275.0 287.6 294.0 295.1 318.3 243.0 238.7 219.7 206.9] → 2628.1
这里我们slice中的每个元素增加5%. 然后进行计算总和。
slice当然也可以包含自定义元素。 以下这个例子,是一个只包含一个方法的自定义类型
type Product struct {
name string
price float64
}
func (product Product) String() string {
return fmt.Sprintf("%s (%.2f)", product.name, product.price)
}
这里定义了一个Product类型,它包含了string和float64类型的两个字段。 我们同样定义了一个String()方法,用于在使用%v时,控制Product元素的输出。
products := []*Product{{"Spanner", 3.99}, {"Wrench", 2.49},
{"Screwdriver", 1.99}}
fmt.Println(products)
for _, product := range products {
product.price += 0.50
}
fmt.Println(products)
/*
[Spanner (3.99) Wrench (2.49) Screwdriver (1.99)]
[Spanner (4.49) Wrench (2.99) Screwdriver (2.49)]
*/
这是我们创建了一个指向到Products的指针数组。 并且立即初始化三个*Products元素. 为什么在没有使用取址符&时,也可以初始化指针呢,这是因为Go足够的聪明,它可以知道一个[]*Product 需要的是指向到Products的指针。 这种写法只是products := []*Product{&Product{"Spanner", 3.99}, &Product{"Wrench", 2.49}, &Product{"Screwdriver", 1.99}}. 的简写。
如果没有定义Product.String() 方法, 那么%v 将简单的输出Product内存的地址. 需要注意的是,Prodcut.String 的参数是Product 的值,而不是指针*Product. 但不用担心, 由于Go足够的智能,可以解引用(derefernce), 使得它可以在调用自定义方法时传入Product的值。(同对struct指针属性赋值,"."操作符也可以自动解引用)
注:编译器在创建一个接受值的方法时,也会创一个同样签名,接受指针操作的方法 func (value *Type) Method() { return (*value).Method() }.
我们之前提及过 for ... range循环不能修改item的值, 但在这里,我们去成功的修改了products slice的每一个值。 这是因为每一个遍历,都是复制*Product(指针);
Modifying Slices
如果我们需要为一个slice添加元素,可以使用内置的append()函数。 这个函数第一个参数是目标slice, 之后的参数是一个或者多个单独的元素。 如果我们需要将一个slice,添加到另一个slice. 必须使用 ...(省略号)操作符, 告诉Go被添加(源)slice分隔成多个单独的值,然后添加到目标slice. 被添加的值,必须跟目标slice要求的类型一致。对于字符串来说,我们可以通过使用...(省略号),将每个字符添加到一个byte slice中。 如下所示
s := []string{"A", "B", "C", "D", "E", "F", "G"}
t := []string{"K", "L", "M", "N"}
u := []string{"m", "n", "o", "p", "q", "r"}
s = append(s, "h", "i", "j") // Append individual values
s = append(s, t...) // Append all of a slice's values
s = append(s, u[2:5]...) // Append a subslice
b := []byte{'U', 'V'}
letters := "wxy"
b = append(b, letters...) // Append a string's bytes to a byte slice
fmt.Printf("%v\n%s\n", s, b)
/*
[A B C D E F G h i j K L M N o p q]
UVwxy
*/
内置append()函数原理是接一个slice(a)和一个或者多个(value)需要添加到 slice的值。并返回一个slice(b), 返回的这个slice(b)包含原来slice(a)的所有值,并将value添加到slice(b)后面。 如果 slice(a)的容量足够容下这些新值(隐藏数组), append() 会将新的value 或者values放到一到slice(a)之后的位置, 并增加length+ value的个数. 如果capacity不够,将创建一个新的隐藏数组, 并将原来slice的值复制到新的数组。同时将value或values添加到新的数组. 以下是capacity 不足与足的两个不同情况
s := []string{"A", "B", "C", "D", "E", "F", "G"}
t := append(s[:1], "1") // 小于capacity, 所以直接在将"1"添加到s[0]的后面,最终修改了隐藏数组的值s[1]的值
fmt.Println(s) //[A 1 C D E F G]
fmt.Println(t) // [A 1]
s := []string{"A", "B", "C", "D", "E", "F", "G"}
t := append(s[:1], "H", "I", "J", "K", "M", "N", "L") // 要添加的元素, 超过 cap(s), 所以t的slice是基于新创建的隐藏数组 s的值末改变
fmt.Println(s) //[A B C D E F G]
fmt.Println(t) // [A H I J K M N L]
有时,我们可能需要将slice添加到另一个slice之前面或者中间, 而不仅仅是后面。 这里有一些例子,使用到自定义的函数InsertStringSliceCopy()。 它接收一个要插入到的slice(目标). 一个被插入的slice(source). 以及要插入的位置。
s := []string{"M", "N", "O", "P", "Q", "R"}
x := InsertStringSliceCopy(s, []string{"a", "b", "c"}, 0) // At the front
y := InsertStringSliceCopy(s, []string{"x", "y"}, 3) // In the middle
z := InsertStringSliceCopy(s, []string{"z"}, len(s)) // At the end
fmt.Printf("%v\n%v\n%v\n%v\n", s, x, y, z)
/*
[M N O P Q R]
[a b c M N O P Q R]
[M N O x y P Q R]
[M N O P Q R z]
*/
自定义的InsertStringSliceCopy()函数创建一个新的slice(这也是为什么slice s没有被改变).
func InsertStringSliceCopy(slice, insertion []string, index int) []string {
result := make([]string, len(slice)+len(insertion))
at := copy(result, slice[:index])
at += copy(result[at:], insertion)
copy(result[at:], slice[index:])
return result
}
内置的copy()函数接受两个包含相同类型元素的slices(可能为相同slice中的不同部分——即使有重叠部分)。 这个函数将第二个参数(source slice)中的元素复制到第一个参数(destination), 并返回复制的个数。如果source slice 为空,copy()函数将什么也不做。 如果destination slice的length不足以包含source的元素。那么超出的部分将会被忽略。如果destination slice的容量比length大, 我们在可以复制之前,通过slice=slice[:cap(slice)]增加它的长度。
s := make([]int, 2, 7)
s[0], s[1] = 3, 4
at := copy(s, []int{1, 2, 3})
fmt.Println(s)
fmt.Println(at)
// [1 2]
// 2
传递给copy()函数的两个参数必须是相同类型,除了字符串与[]byte. 如果第一个参数(destination)是一个[]byte,而第二个(source)出的数可以为[]byte或者string. 如果source是string. 它的字节将复制到第一个参数。
如果index位置为0, 则slice[:index]在第一次复制语句中为slice[:0](i.e.,一个空slice). 所以什么都没有复制,相似的,如果index 大于或等于slice的长度,则最后一条复制语句slice[index:]等同于slice[len(slice):](i.e., 一个空的slice). 同样什么也没有复制.
这里还有一个类似的函数InsertStringSlice. 与copy不同的在于 InsertStringSlice函数会改变original slice。 而InsertStringSliceCopy是创建了一个新的slice,而不会改变原来slice。
func InsertStringSlice(slice, insertion []string, index int) []string {
return append(slice[:index], append(insertion, slice[index:]...)...)
//返回slice(第一个参数)的隐藏数组的另一个slice(相当于相同数据库表的另一个视图
}
从slice中删除首部和尾部的元素非常简单,但对于中间的元素,却需要注意一下。我们先看看如何在slice原位删除首部,中部和尾部的元素。 然后我们将看到如何先复制要删除的元素,而原始的slice没有被改变.
s := []string{"A", "B", "C", "D", "E", "F", "G"}
s = s[2:] // Remove s[:2] from the front
fmt.Println(s)
//[C D E F G]
s := []string{"A", "B", "C", "D", "E", "F", "G"}
s = s[:4] // Remove s[4:] from the end
fmt.Println(s)
//[A B C D]
s := []string{"A", "B", "C", "D", "E", "F", "G"}
s = append(s[:1], s[5:]...) // Remove s[1:5] from the middle
fmt.Println(s)
//[A F G]
显然,以上的方法都会修改到original slice. 为了不修改s, 可以定义了RemoveStringSlice
s := []string{"A", "B", "C", "D", "E", "F", "G"}
x := RemoveStringSliceCopy(s, 0, 2) // Remove s[:2] from the front
y := RemoveStringSliceCopy(s, 1, 5) // Remove s[1:5] from the middle
z := RemoveStringSliceCopy(s, 4, len(s)) // Remove s[4:] from the end
func RemoveStringSliceCopy(slice []string, start, end int) []string {
//方法不会改变 s 的值
result := make([]string, len(slice)-(end-start))
at := copy(result, slice[:start])
copy(result[at:], slice[end:])
return result
}
fmt.Printf("%v\n%v\n%v\n%v\n", s, x, y, z)
/*
[A B C D E F G]
[C D E F G]
[A F G]
[A B C D]
*/
同样,也可以创建一个类似的方法, 但会修改s的值
func RemoveStringSlice(slice []string, start, end int) []string {
return append(slice[:start], slice[end:]...)
}
Sorting and Searching Slices
标准库中的sort package 提供了对ints, float64s, strings slices的排序的方法, 也提供了检验一个slice是否为已排序的方法, 同样提供了在一个已排序的slice进行搜索的方法,并且是使用最快的二分法搜索算法。 这里也有通用的sort.Sort() 和 sort.Search()函数,可以用于自定义数据。 这些函数如表4.2所示
对于数字排序来说,都没有什么问题需要注意的,但对于字符串排序, 其实是对代表字符串的字节进行排序。所以字符串的排序是有大小写区分的。
files := []string{"Test.conf", "util.go", "Makefile", "misc.go", "main.go"}
fmt.Printf("Unsorted: %q\n", files)
sort.Strings(files) // Standard library sort function
fmt.Printf("Underlying bytes: %q\n", files)
SortFoldedStrings(files) // Custom sort function
fmt.Printf("Case insensitive: %q\n", files)
/*
Unsorted: ["Test.conf" "util.go" "Makefile" "misc.go" "main.go"]
Underlying bytes: ["Makefile" "Test.conf" "main.go" "misc.go" "util.go"]
Case insensitive: ["main.go" "Makefile" "misc.go" "Test.conf" "util.go"]
*/
Table 4.2 The Sort Package’s Functions
| Syntax | Description/result |
|---|---|
| sort.Float64s(fs) | Sorts fs of type []float64 into ascending order |
| sort.Float64sAreSorted(fs) | Returns true if fs of type []float64 is sorted |
| sort.Ints(is) | Sorts is of type []int into ascending order |
| sort.IntsAreSorted(is) | Returns true if is of type []int is sorted |
| sort.IsSorted(d) | Returns true if d of type sort.Interface is sorted |
| sort.Search(size, fn) | Returns the index position in a sorted slice in scope of length size where function fn with the signature func(int) bool returns true (see text) |
| sort.SearchFloat64s(fs, f) | Returns the index position of f of type float64 in sorted fs of type []float64 |
| sort.SearchInts(is, i) | Returns the index position of i of type int in sorted is of type []int |
| sort.SearchStrings(ss, s) | Returns the index position of s of type string in sorted ss of type []string |
| sort.Sort(d) | Sorts d of type sort.Interface (see text) |
| sort.Strings(ss) | Sorts ss of type []string into ascending order |
| sort.StringsAreSorted(ss) | Returns true if ss of type []string is sorted |
sort.Strings() 函数接受一个[]string slice,并且依束代表字符串的底层字节顺序,就地升序排列。 如果字符是经过相同的字符编码(e.g 它们都是在当前程序或者其它go 程序), 结果则是字符码(unicode字符编码表)的顺序。 SortFoldedStrings()除了调用sort包中通用的sort.Sort()函数,可以进行大小写无关的排序,其它都是一样的。
sort.Sort()函数可以对任意类型的slice进行排序。 只要这种类型提供的方法符合sort.Interface(Len(), Less(), Swap(),每一个方法有所需的签名). 我们先创建了一个自定义类型, FoldStrings, 它提供了以上三个方法。 以下是完成的SortFoldedString函数, FoldedStrings 类型以及所要支持的sort.Interface的方法
func SortFoldedStrings(slice []string) {
sort.Sort(FoldedStrings(slice))
}
type FoldedStrings []string
func (slice FoldedStrings) Len() int { return len(slice) }
func (slice FoldedStrings) Less(i, j int) bool {
return strings.ToLower(slice[i]) < strings.ToLower(slice[j])
}
SortFoldedStrings()函数只是简单的调用标准库中的sort.Sort()函数, 并且将一个string slice转化为FoldedStrings(非常廉价). 通常,当我们创建的自定义变量是依于内置的类型时,我们可以将内置类型的值通过这种方式提升到自定义变量(拥有额外的方法)。
FoldedStrings类型提供了三个满足sort.Interface接口要求的方法。 三个方法都非常简单,忽略大小是是通过Less()方法中的strings.ToLower()函数。(如果我们需要降序,我们只需要简单的将小于 < 操作符, 替换为 大于 > 操作符)。
如果我们需要在一个slice中搜索一个元素,然后返回相应的位置, 可以使用 for ... range
files := []string{"Test.conf", "util.go", "Makefile", "misc.go", "main.go"}
target := "Makefile"
for i, file := range files {
if file == target {
fmt.Printf("found \"%s\" at files[%d]\n", file, i)
break
}
}
//found "Makefile" at files[2]
使用简单的线性搜索是对未排序数据的唯一方法,也适用于小的slices(可以多达数百项). 但对于大的slices, 特别是对于重复查找的, 线性搜索非常不高效。平均每次都需要比较一半的元素。
Go 提供了 sort.Search()方法,它使用的是二分法算法。每次它仅需要比较log2(n)。 为了更好的理解,我们举个例子, 对于1 000 000 个元素的slice来说,需要500000的比较, 最坏情况下,需要1000000次比较,而如果是二分法查找, 即使在最坏情况下,也只需要20次比较
sort.Strings(files)
fmt.Printf("%q\n", files)
i := sort.Search(len(files),
func(i int) bool { return files[i] >= target })
if i < len(files) && files[i] == target {
fmt.Printf("found \"%s\" at files[%d]\n", files[i], i)
}
/*
["Makefile" "Test.conf" "main.go" "misc.go" "util.go"]
found "Makefile" at files[0]
*/
sort.Search()函数接受两个参数, 一个length(搜索的长度),这里是整个slice, 另一个是一个比较函数, 比较函数是对排序好的slice中的元素与与target(要搜索的目标字符串)进行比较,如果 >= , 则表明slice为升序,如果是<= 则为降序. sort.Search()函数会返回一个int. 在最后一步,我们需要确认 int是否大于len, 并且在int这个位置的元素正好是我们需要找的,我们才能确认,这是我们需要找到的位置
以下是一个不关大小写的搜索, 并且假定要搜索的字符串为小写
target := "makefile"
SortFoldedStrings(files)
fmt.Printf("%q\n", files)
caseInsensitiveCompare := func(i int) bool {
return strings.ToLower(files[i]) >= target
}
i := sort.Search(len(files), caseInsensitiveCompare)
if i < len(files) && strings.EqualFold(files[i], target) {
fmt.Printf("found \"%s\" at files[%d]\n", files[i], i)
}
/*
["main.go" "Makefile" "misc.go" "Test.conf" "util.go"]
found "Makefile" at files[1]
*/